文章来自于公众号:数字化深度思考者
近期Deepseek爆🔥,一时之间,似乎人人都在谈Al,周末再次作个简单易懂的大模型和Al科普。
近期很多用Deep seek R1生产word或PPT的例子,其实未有Al之时,WPS本身就提供有海量参考模板,内容生成会使人们变懒,懒惰亦是人之天性,尤其是大学毕业论文,以中国大部分大学的尿性和脱离社会实践,本科四年大部分学生的论文都相当雷同,再Al生成,批量造假,就很不好了。
现在全网都在讨论Deep seek R1的文生内容,先不谈技术实现,换个思路,它可以看一个升级版的智能搜索+内容生成,比如你不是lT专业,完全不懂大模型,那可以用搜索引擎搜出一堆关于大模型的网页,然后自己审核和筛选下相关内容组织一篇文章,现在deep seek等Al工具将搜索和写文章合并在一起,效率是高了,但你还得审核吧,哦,现在不审核了,直接copy and paste,交差了事!😋😋
腾讯混元开源↓
Deep seek带了个好头,近期腾讯开源,百度开源

机器学习
传统的AI机器学习,是统计学上的概念,比如 逻辑回归(LR),支持向量机(SVM),决策树模型,机器学习是人工智能的一个重要子领域,侧重于利用数据和统计方法让计算机系统自动学习和改进。
深度学习和神经网络
深度学习通常和神经网络放在一起,两者既有联系又有区别!深度学习泛指深度神经网络,意思就是深度的神经网络,是多层的神经网络,而不是传统的单层或两层。与其说深度学习是机器学习的一种,不如说是一种进化。
有人说现在机器学习与深度学习的区分已经不明显了,深度学习也用到机器学习的算法模型。深度学习,在神经网络的基础上,有了更多的层级,以前传统的神经网络,一般有2-3层,而深度学习,可以有更多层,至于能有多少层,需要根据实际的业务而定。
在深度学习中,梯度消失和梯度爆炸是训练深层神经网络时常见的两大问题,它们会严重影响网络的训练过程和性能。
梯度消失(Vanishing Gradient)
梯度消失是指在深层神经网络的反向传播过程中,梯度值随着层数的增加而迅速减小,最终趋近于零。这会导致靠近输入层的权重更新变得非常缓慢,甚至几乎不更新,从而阻止网络从输入数据中学习有效的特征表示。
梯度爆炸(Exploding Gradient)
梯度爆炸是指在训练深度神经网络时,反向传播过程中,梯度的值变得异常大,导致参数更新过大,甚至出现溢出的现象。这个问题会导致网络的训练变得不稳定,甚至无法收敛。
TensorFlow 和 PyTorch 是目前最流行的深度学习框架,TensorFlow 和 PyTorch 都非常适合用于开发和训练 Transformer 模型。
不深入细讲,非lT专业开始听不懂了!
(三)、大模型概念和分类
大模型(Large Models,LM):大模型通常指的是具有大量参数的机器学习模型特别是深度学习模型。
大模型的特点是参数数量巨大,通常在百万到数十亿级别;能够处理和理解大量的数据;通常具有较高的泛化能力,能够处理未见过的新数据,数据、训练(如人的学习过程)、模型关系!
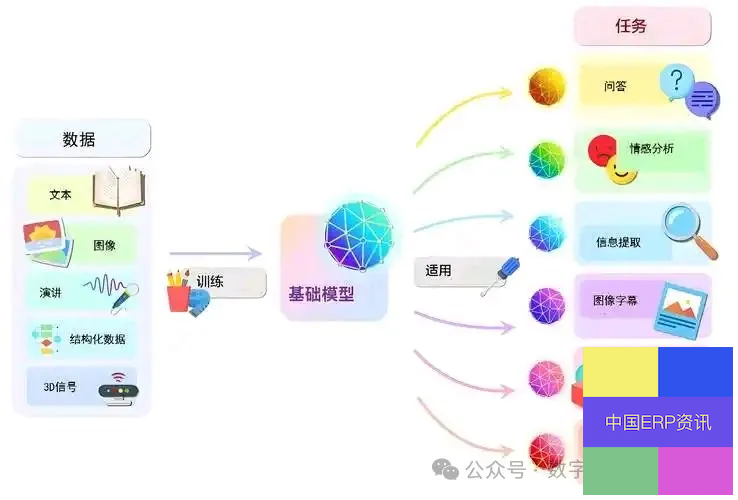
大模型分类
(1).大模型按输入数据类型分为语言大模型(其代表为LLM)、视觉大模型(CV )和多模态大模型;
(2).大模型按应用领域分为通用大模型(L0)、行业大模型(L1)和垂直大模型(L2)。
科普完毕,如果想更深入了解,就是算法,再进一步就是开发工具和编程语言实现,术业有专攻,非lT专业人士没有必要去学习!
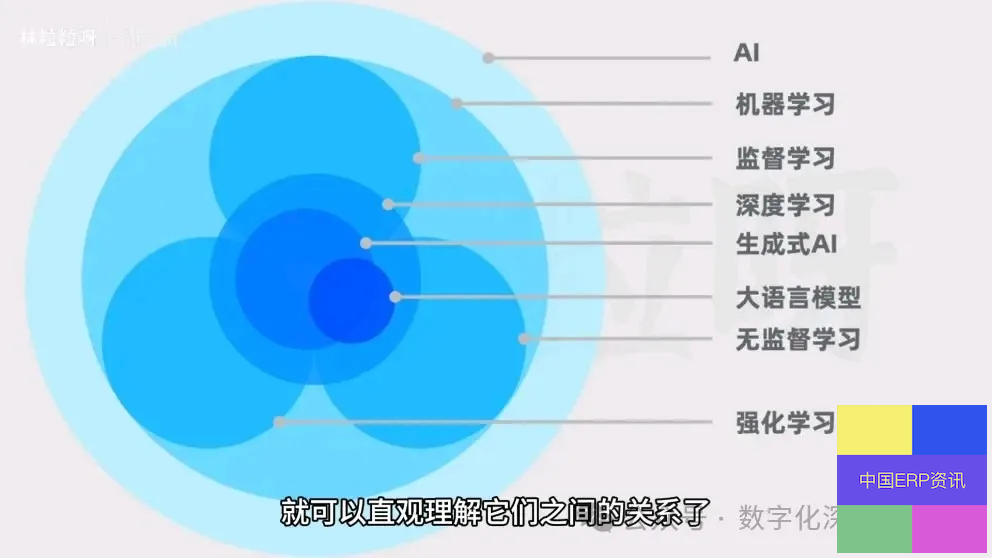
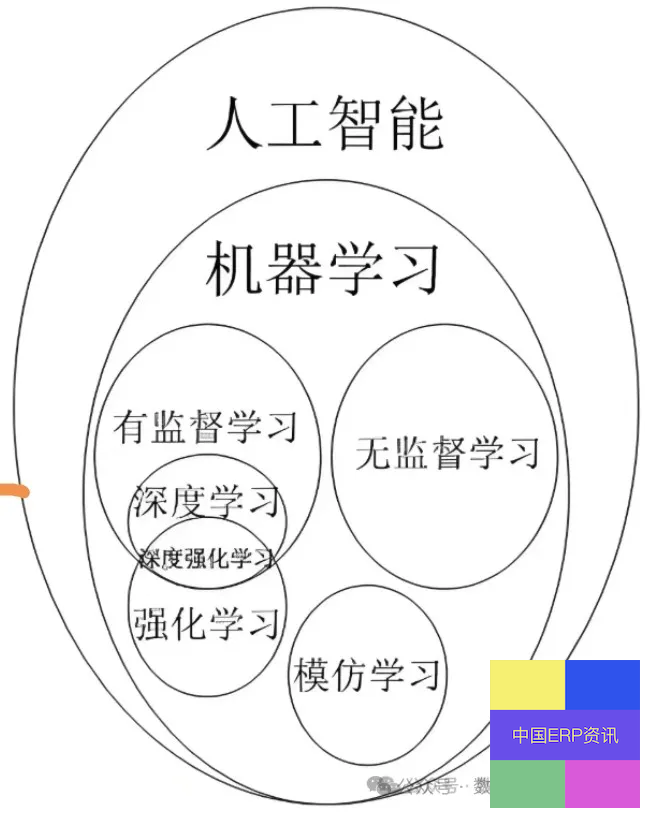
最后Al、机器学习(含深度学习)、AlGC生成式Al(含大语言模型LLM)的关系如下图!